
Article ReMix
Fictions et (con)figurations: réflexions sur la constitution de bases de données pour les études littéraires


Un nuage de mots sur le Gremlin
(Credit : Gremlin)
«Like it or not, today’s literary-historical scholar can no longer risk being just a close reader: the sheer quantity of available data makes the traditional practice of close reading untenable as an exhaustive or definitive method of evidence gathering. Something important will inevitably be missed. The same argument, however, may be leveled against the macroscale; from thirty thousand feet, something important will inevitably be missed. The two scales of analysis, therefore, should and need to coexist.»
– Matthew Jockers, Macroanalysis: digital methods and literary history
Introduction
Nous présentons dans cet article le bilan de la constitution de la base de données Figurations, une infrastructure de recherche numérique créée par le Groupe de recherche sur les médiations littéraires et les institutions (Gremlin). Nous cherchons à atteindre, par la publication de ce bilan, deux objectifs: bien faire ressortir la valeur et, surtout, l’originalité de Figurations et éclairer les décisions de chercheurs qui songent à concevoir eux aussi une base de données pour mener à bien des projets de recherche en études littéraires.
Ce texte est divisé en deux parties distinctes. Nous ferons tout d’abord, et ce, afin de mieux faire ressortir la spécificité de la base Figurations, un rapide tour d’horizon de la façon dont les bases de données ont été et sont mobilisées en études littéraires. Ce bref tour d’horizon achevé, nous nous arrêterons à la base elle-même, à sa structure et à son contenu, et expliquerons certains choix posés dans le cadre de sa conception. Nous montrerons ensuite comment l’encodage de nos données de recherche dans cette base favorise leur exploitation tout en prenant bien soin de souligner et d’interroger les limites de notre outil. Nous conclurons ce bilan par quelques recommandations visant à maximiser le potentiel de diffusion et de réutilisation de nos données de recherche.
Études littéraires et bases de données: quelques repères
Cette brève présentation des principaux usages du numérique en études littéraires est structurée en fonction d’une typologie que nous avons proposée dans un article paru en 2012 et qui permet de catégoriser les bases de données en histoire et en sociologie de la culture en fonction de l’importance relative qu’elles accordent à «trois des entités sociales explorées par les sciences humaines et sociales: les attributs, les relations et les textes». (Dozo, 2012: 43) Certaines bases de données sont textuelles, d’autres sont attributives et d’autres, enfin, sont relationnelles. Cette catégorisation n’est pas, bien évidemment, tranchée. Nombre de bases de données en études littéraires accordent autant d’importance à deux ou même à toutes ces dimensions. Malgré son caractère abstrait et un peu réducteur, cette typologie nous semble féconde en ce qu’elle permet de mettre en lumière la très grande majorité des utilisations possibles de cet outil informatique dans le champ des études littéraires.
Les bases de données textuelles
Les bases de données textuelles constituent l’un des usages les plus répandus de l’informatique en études littéraires. En fait, depuis les travaux pionniers de Roberto Busa1Roberto Busa est un prêtre jésuite italien qui s’est donné pour mission, en 1946, d’étudier le lexique de la présence et de l’incarnation dans les œuvres de Saint-Thomas d’Aquin, vaste corpus de plus de onze millions de termes. Aidé en cette tâche par IBM (International Business Machines Corporation), il effectua une lemmatisation complète du corpus aquinien, aventure qui dura plus de trente ans et qui aboutit à la constitution du Corpus thomisticum qui est aujourd’hui consultable en ligne, dans sa version latine origine, à l’adresse http://www.corpusthomisticum.org/. , jusqu’à ceux, non moins révolutionnaires, de Franco Moretti et de ses collègues du Stanford Literary Lab, en passant par la mise en place des premiers grands corpus textuels informatisés tels le Brown Corpus for Use on Digital Computers2Premier corpus de texte en anglais contemporain, le Brown Corpus for Use On Digital Computers fut mis en place dans les années 60 à l’Université de Brown par W. Nelson Francis et Henry Kučera. , le Thesaurus Lingua Graecae 3Le Thesaurus Lingua Graecae, mis en place en 1972, contient les principaux textes de l’antiquité grecque depuis Homère jusqu’à l’an 200 après Jésus-Christ. , l’Oxford Text Archive4L’Oxford Text Archive a été mise sur pied en 1976 par Lou Burnard, qui s’était donné pour mission d’archiver et de rendre accessibles à qui en avait besoin des copies électroniques de textes encodés préalablement par d’autres chercheurs pour des projets spécifiques. et Frantext5Cette base de données a été créée au cours des années 70 afin de fournir des exemples pour le Trésor de la Langue Française et qui a alimenté dans les décennies suivantes un nombre impressionnant de travaux de lexicométrie et d’analyse textuelle automatisée. , la création et la mobilisation de ce type de bases de données constituent l’un des principaux vecteurs de développement des humanités numériques. Nous n’avons qu’à se rappeler, pour s’en convaincre, l’impact qu’ont eu et que continuent d’avoir sur le champ des études littéraires les grandes entreprises de numérisation et d’océrisation menées par les bibliothèques nationales telles la British Archive, la Library of Congress, la Bibliothèque nationale de France et Bibliothèque et Archives nationales du Québec. Les chercheurs en études littéraires se trouvent aujourd’hui confrontés à une innombrable quantité de textes littéraires et journalistiques numérisés et répartis dans une multitude de bases de données de toutes sortes. Certaines de ces bases proposent à leurs usagers le contenu textuel brut des œuvres, alors que d’autres rendent accessibles des versions annotées, sémantisées des textes ciblés. C’est le cas, par exemple, des nombreuses éditions électroniques réalisées par l’Orlando Project6Fondé en 1997, le Orlando Project est accessible à l’adresse http://www.artsrn.ualberta.ca/orlando/. , consacré aux écrivaines des îles britanniques, ainsi que par HyperRoy7Le site web du projet est accessible à l’adresse http://hyperroy.nt2.uqam.ca. , projet d’édition électronique de manuscrits et de textes inédits de Gabrielle Roy.
Les technologies de stockage pouvant être mises à profit pour mettre en place une base de données de ce type sont assez variées: fichiers texte, bases de données relationnelles telles MySQL ou Microsoft Access, bases de données NoSQL orientées documents et, enfin, fichiers et bases de données XML.
Cette dernière technologie constitue le principal format utilisé pour la réalisation d’éditions numériques de textes littéraires annotés. Elle est associée, en effet, de façon fondamentale à la Text Encoding Initiative (TEI), dont l’histoire remonte en 1987, année au cours de laquelle des chercheurs du monde entier, préoccupés par la multiplication effrénée de bases de données textuelles, se sont entendus sur la nécessité de mettre en place un modèle unifié de représentation des éléments signifiants d’un texte. Ce modèle est décrit dans les Guidelines for Electronic Text Encoding and Interchange, dont la première version fut publiée en mai 1994.
Une grande partie des corpus textuels annotés qui ont été mis en place depuis lors ont mis en œuvre les recommandations de la TEI. Ces éditions de textes numériques sont réalisées en XML, le format préconisé par cet organisme. Les documents encodés dans ce format sont structurés de façon hiérarchique à l’aide de balises encadrées par des chevrons. Ces balises permettent d’annoter, à même le texte, les œuvres ciblées. Les frontières d’un mot peuvent ainsi être signalées par la balise <w>, la présence d’un espace par la balise <space>, une correction apportée à une section du texte par l’encodeur par la balise <corr>, etc. À chacune de ces balises peuvent être associés des attributs dont l’usage permet de bonifier davantage la sémantisation du texte étudié. On peut ainsi indiquer, par exemple, en utilisant l’attribut «lemma» sur une balise <w>, le lemme auquel peut être rapporté le mot concerné.
L’adoption de la norme XML-TEI par un projet de recherche présente plusieurs avantages non négligeables dont la maximisation du potentiel de diffusion et de réutilisation des documents produits, la séparation du contenu textuel et de son affichage potentiel et, enfin, la richesse de la sémantisation des textes qu’elle permet. Notons cependant que le processus de création de documents XML-TEI requiert un investissement de temps et d’énergie extrêmement important, à la fois au niveau de la création des documents eux-mêmes, création qui nécessite généralement l’emploi d’un logiciel propriétaire tel Oxygen, mais aussi au niveau de la formation des personnes chargées de l’encodage des données. Ce facteur constitue d’ailleurs, selon Susan Brown, directrice technique de l’Orlando Project, un frein à l’adoption massive de ce modèle de données:
[T]he size of the TEI community is limited by the complexity of the data model and the tools required to implement it, with the result that simpler, procedurally oriented text editing systems such as wikis and WordPress have garnered more mainstream scholarly users. When what the average scholar wants above all is usability in scholarly tools and interoperability in scholarly resources, there is a tension between more usable technologies and those based on better data models and best practices. (291)
De plus, nombreux sont celles et ceux qui croient que ce modèle manque de souplesse et qu’il ne permet pas toujours de rendre compte de la richesse des phénomènes textuels à l’étude. Ce caractère contraignant des normes d’encodage telles que celles proposées par la TEI a d’ailleurs été soulevé récemment par Jean-Guy Meunier dans un article consacré aux enjeux herméneutiques du texte numérique:
s’il est facile de s’entendre sur le fait qu’une suite linguistique particulière est un verbe ou un titre, il n’en va pas de même lorsque différentes interprétations linguistiques, discursives, énonciatives ou socio-psychologiques sont sollicitées. En conséquence, il est difficile de proposer des types universels ou tout au moins généraux d’annotations, d’où le caractère fortement subjectif de tout projet d’annotation: à chaque utilisateur ou groupe d’utilisateurs son système d’annotation. Face à cette situation, certains projets ont rejeté toute standardisation des annotations, lui préférant plutôt des marquages hybrides ou ad hoc. Ce type d’approche semble par ailleurs celle qui est devenue la plus acceptable et la plus pratiquée. (Meunier, 2018)
Ce manque de souplesse du modèle proposé par la TEI s’explique en partie par son association avec la technologie XML. Ainsi, comme l’a souligné le responsable du Skaldic Project8Ce projet vise à mettre en place une édition électronique du corpus de la poésie scaldique qui contient près de 5800 stances en vieux norrois. , Tarrin Wills, dans un article au sein duquel il explique son rejet de cette technologie au profit de la mise en place d’une base de données relationnelle, le format XML, fondé sur un strict modèle hiérarchique, n’est pas adapté à l’encodage de données relationnelles relativement complexes: «Links can be made anywhere in the XML document […] but these do not define the semantic relationship between the reference and identifier, which is implied by the relational database structure.» (Wills: 311)
Comme l’un des principaux objectifs du projet de recherche à l’origine de Figurations est l’analyse des configurations, des «systèmes d’interactions» qui se tissent au sein des œuvres «entre les figures d’acteurs littéraires fictifs» (Gremlin, 2010), cette lacune de la solution XML-TEI nous est apparue pour le moins problématique et nous avons donc choisi, à l’instar de Wills et de ses collègues, de mettre en place dans le cadre de ce projet un modèle de données créé sur mesure et hébergé dans un système de gestion de base de données (SGBD) relationnel, libre et gratuit: MySQL.
La longue histoire des bases de données textuelles ainsi que leur polyvalence expliquent le foisonnement des outils et méthodes accessibles à tout chercheur en études littéraires qui souhaite exploiter ce type de données: lexicographie, stylométrie, concordances et lemmatisation, analyse des cooccurrences, topic modeling, analyse de sentiments, etc.
Un ensemble de méthodes apparentées se détache néanmoins du lot en ce qu’il jouit d’une forte popularité depuis quelques années: la fouille de textes (text mining). Ces méthodes permettent l’exploration et l’analyse automatisée de corpus textuels, généralement de très grande envergure, pouvant contenir jusqu’à plusieurs millions de documents textuels. C’est le cas, par exemple, de la technique du text clustering, qui permet de regrouper de façon automatique des documents textuels en fonction de certains paramètres définis par le chercheur. On pourrait ainsi vouloir regrouper des textes en fonction de la fréquence relative de certains mots-clés ou bien en fonction de l’usage qu’ils font de la ponctuation.
Autre technique associée à la fouille de textes, l’apprentissage supervisé représente le contraire du text clustering en ce que c’est l’usager qui fournit au logiciel utilisé les classes dans lesquelles devront être repartis les objets textuels à l’étude, ainsi que les exemples qui permettront à l’ordinateur de construire les modèles de classification nécessaires. C’est la méthode employée par Moretti (Allison et al.) et ses collègues dans le cadre du projet de recherche qui fait l’objet du premier Pamphlet du Stanford Literary Lab et qui aboutit à la création d’un logiciel, Docuscope, capable de reconnaître le genre auquel appartient un roman.
Autre approche associée à la grande famille de la fouille de textes, le topic modeling permet d’inférer à partir d’un texte ou d’un corpus de textes les principales thématiques qui y sont mobilisées et d’en repérer les passages les plus significatifs.
Les diverses techniques énumérées ci-dessus peuvent être mises en œuvre à l’aide de logiciels spécialisés tels Mallet, Weka 3 et Gensim. Certains plugiciels du logiciel d’analyse statistique R offrent aussi des fonctionnalités de ce type. Mentionnons aussi, enfin, la suite logicielle Voyant Tools qui permet d’effectuer toutes sortes d’analyses relativement sophistiquées sur des documents textuels directement dans un navigateur web.
Les bases de données attributives
À l’instar des bases de données textuelles, les bases de données attributives, ces bases qui regroupent des informations généralement quantifiables portant sur les attributs, les caractéristiques des objets ciblés, sont intimement liées à l’histoire du développement des humanités numériques. Cependant, contrairement aux bases de données textuelles, qui étaient plutôt réservées aux linguistes et aux littéraires, ce type de bases de données fut pendant longtemps surtout mobilisé par des historiens et des sociologues qui se trouvaient en mesure de traiter de façon globale et relativement simple d’impressionnantes quantités de données. Plusieurs chercheurs associés à l’École des Annales ont ainsi fait, dès les années 60, une utilisation intensive de l’informatique et des bases de données attributives pour mener à bien des recherches de grande envergure, qui n’auraient pu être menées autrement. Ces travaux, comme l’a rappelé Frédéric Clavert dans un article fort intéressant consacré à l’usage de l’informatique en histoire (2014), ont eu un impact majeur sur le développement des humanités numériques. L’usage des bases de données attributives a par la suite essaimé dans le champ des études littéraires et, en particulier, en histoire littéraire.
Deux types de bases de données attributives sont ainsi souvent mobilisés dans le cadre de projets de recherche de cette nature: les bases de dépouillement qui ciblent des ensembles de productions culturelles décrites dans les moindres détails et les bases de données prosopographiques qui s’arrêtent plutôt aux acteurs. Le premier type s’incarne dans des bases de données telles Prelia9Prelia est accessible en ligne à l’adresse http://prelia.fr. , qui recense plusieurs milliers d’articles publiés dans des revues d’art parues en 1870 et 1940 ainsi que dans le Répertoire10Ce répertoire est accessible en ligne à l’adresse http://nt2.uqam.ca. mis en place par le Laboratoire de recherche sur les œuvres hypermédiatiques (NT2).
Les bases de données prosopographiques visent quant à elles l’établissement d’une prosopographie d’une population donnée, c’est-à-dire qu’elles visent «à décrire une population définie à partir d’un ou de plusieurs critères dans ses dynamiques sociale, privée, publique, voire culturelle, idéologique ou politique.» (Dozo, 2011: 21) Comme exemples de ce type de bases de données, on peut mentionner celle mise en place par le Collectif Interuniversitaire d’Étude du Littéraire et qui recense une quantité impressionnante d’informations sur les trajectoires de plus de cinq cents auteurs belges de langue française actifs entre 1920 et 1960 ainsi que la Base de données sur la Vie littéraire au Québec, créée afin d’appuyer la rédaction des deux prochains tomes de la série d’ouvrages du même nom. On trouve dans ces bases une multitude d’informations concernant les trajectoires des acteurs au sein des champs littéraires ciblés: les publications, les prix et récompenses obtenus, les formations suivies, les occupations, les lieux de résidence, etc.
Les données attributives sont généralement stockées dans des SGBD relationnels tels MySQL, PostgreSQL, Microsoft Access ou FileMaker, logiciels qui facilitent grandement leur mise en série et leur analyse. Cette analyse peut être effectuée à l’aide de nombreux outils et méthodes. Deux de ces méthodes, une plus classique et l’autre plus tardive, jouissent d’une certaine popularité au sein du champ des études littéraires: l’analyse factorielle des correspondances multiples (ACM) et la cartographie numérique.
La mise en série des informations colligées dans les bases de données attributives permet, grâce à des méthodes associées à l’analyse quantitative, de mettre au jour des informations inédites, que la simple analyse qualitative des données recensées ne permet pas de repérer. Les interfaces de consultation de ces bases mettent généralement en place un outil de recherche qui permet d’interroger de façon très précise les données recueillies et de produire des statistiques assez complètes. Ce type d’outil de recherche a cependant ses limites. C’est pourquoi il peut être utile de recourir, afin de raffiner les statistiques ainsi produites, à des méthodes quantitatives plus poussées, dont, par exemple, l’analyse factorielle des correspondances qui peut être convoquée avec profit dans l’analyse des données d’une base de ce type. Une variante de l’analyse factorielle des correspondances, l’analyse des correspondances multiples permet ainsi d’explorer, en les projetant sur un plan à deux dimensions, les liens potentiels entre plusieurs variables, fonctionnalité qui fait de l’ACM un outil exploratoire extrêmement puissant. L’usage de cette méthode est très répandu en sociologie et en histoire de la littérature, en particulier dans les travaux de chercheurs associés à l’école bourdieusienne tels ceux, exemplaires, de Gisèle Sapiro (1999). Notons que l’apprentissage de cette méthode d’analyse et des logiciels d’analyse statistique (R, SPSS, XLStat) associés n’est pas de tout repos et nécessite un investissement de temps assez important.
La cartographie numérique, autre méthode d’analyse des données attributives à laquelle nous consacrerons quelques lignes, est généralement de prise en main beaucoup plus aisée. En effet, bien rares sont ceux qui n’utilisent pas, au moins une fois par semaine, une application de géolocalisation. Depuis l’arrivée de Google Maps, en 2005, cette technologie fait en effet partie de nos vies. La démocratisation de cette technologie a aussi bouleversé le champ des humanités numériques si bien que l’on parle maintenant d’un «spatial turn in the humanities» provoqué par ce développement. C’est l’impact de cette démocratisation des outils de cartographie numérique qu’ont décrit Presner et Sheppard dans leur contribution au New Companion to Digital Humanities:
The expansion to the web, coupled with the availability of satellite imagery, data providers, and map APIS from Google to OpenLayers, took away the time-consuming aspect of having to acquire basemaps and learn abstruse software. It empowered an entire generation of mappers who were now able to create web maps with just a little bit of programming knowledge. (204-205)
On trouve ainsi de nos jours un très grand nombre de projets de recherche en études littéraires qui intègrent cet outil. Citons, par exemple, le projet «Mapping the Republic of Letters11Le site web de ce projet est accessible en ligne à l’adresse http://republicofletters.stanford.edu/. », qui reconstruit les réseaux de correspondance établis par les principales figures de la République des lettres et qui projette ces réseaux sur des cartes géographiques. Mentionnons aussi le groupe Artl@s12Le site web de ce groupe est accessible en ligne à l’adresse http://artlas.ens.fr/fr/. qui coordonne une série de projets de recherche intégrant une approche spatiale et numérique de l’histoire de l’art et de la culture.
L’un des avantages majeurs de l’utilisation de cette méthode dans un projet de recherche en études littéraires consiste en la possibilité de confronter facilement, par leur juxtaposition sur une même carte, des informations de diverses natures. De plus, comme tout ce qui importe est d’être en mesure d’assigner à une information une latitude et une longitude, il est possible d’appliquer cette technique à des œuvres de fiction. Le Laboratoire de recherche sur la culture de grande consommation et la culture médiatique au Québec (LaboPop) a ainsi entamé l’année dernière un projet de recherche qui vise à explorer la façon dont la culture sérielle produite au Québec a représenté l’urbanité et, en particulier, la ville de Montréal. Ce projet, qui a pour corpus principal les séries de romans en fascicules publiés par les éditions Police Journal (1944-1966), permet, grâce à la cartographie numérique, de suivre à la trace l’investissement du tissu urbain par les fictions sérielles et ses personnages.
Les bases de données relationnelles
Contrairement aux deux autres types de bases de données présentés ci-dessus, les bases de données ciblant les relations entre les entités sont apparues récemment dans le champ des études littéraires. Influencés par l’essor de l’analyse des réseaux, plusieurs chercheurs en histoire littéraire ont commencé à se servir des outils et notions développés par les tenants de ce paradigme sociologique pour modéliser, visualiser et analyser les relations entre leurs objets d’étude.
Qu’est-ce que l’analyse des réseaux? En fait, il s’agit d’un programme de recherche qui vise à formaliser, à des fins d’analyse, et ce, à l’aide de la théorie des graphes, les relations entre des entités et qui s’intéresse surtout aux structures formées par ces relations. Les entités à l’étude sont ainsi généralement représentées sur des graphes comme des nœuds liés à un ou plusieurs autres nœuds. Tout peut être pensé et représenté comme un nœud: un individu, un organisme, un film, un lieu, un événement, etc. On trouve, par exemple, en biologie, une utilisation très poussée des concepts développés en analyse des réseaux pour l’étude des interactions entre les molécules au sein d’un organisme.
Les données de ce type peuvent être encodées dans des bases de données relationnelles traditionnelles, telles MySQL ou PostgreSQL, mais le sont souvent dans des bases de données orientées graphe, dont la plus populaire est actuellement Neo4J. De nombreuses solutions logicielles permettent l’analyse et la visualisation de données de ce type, dont Cytoscape, Netminer et, surtout, Gephi.
L’importation de ce paradigme d’analyse dans le champ de l’histoire littéraire, promue par des chercheurs tels Björn-Olav Dozo (2011) ou Michel Lacroix (2003), a surtout ciblé une sous-discipline du grand ensemble de l’analyse des réseaux, l’analyse structurale des réseaux sociaux, discipline qui défend l’hypothèse générale selon laquelle un individu (ou un organisme) est doté d’un avantage compétitif en fonction de sa position au sein d’une structure relationnelle. Certaines positions seraient ainsi très avantageuses alors que d’autres le seraient beaucoup moins. C’est le cas, par exemple, des individus qui occupent des positions intermédiaires, des trous structuraux, entre deux groupes qui n’ont aucun autre lien entre eux. L’analyse structurale des réseaux sociaux propose ainsi plusieurs indicateurs concernant la valeur du «capital social» ou, plutôt, du «capital relationnel» d’un individu. Parmi ces indicateurs, citons, par exemple, la centralité de proximité et la centralité d’intermédiarité. Si l’on passe des individus aux groupes, on peut mettre en évidence, en analysant un réseau d’écrivains, des cliques, des groupes fermés sur eux-mêmes et au sein desquels l’ensemble des liens possibles est réalisé. C’est ce qui se passait, par exemple, dans les cénacles du XIXe siècle, ces «cercle[s] restreint[s] d’écrivains et de peintres animés par des liens d’amitié réciproques et des opinions esthétiques convergentes». (Glinoer: 10) Ce type de configuration sociale se caractérisait par la force des liens unissant les membres de ces groupes qui «se retrouvaient périodiquement chez l’un d’entre eux pour confronter leurs idées, unifier leurs vues et raffermir leur volonté» (Glinoer: 10), mais aussi par une certaine redondance d’informations. Tout le monde avait en effet accès aux mêmes ressources.
On trouve aussi un nombre assez impressionnant de projets de recherche mobilisant ces outils pour visualiser et analyser non pas la structure des relations entre des individus en chair et en os, mais bien plutôt entre des personnages de fiction. Le théâtre de Shakespeare a ainsi fait l’objet ces dernières années de plusieurs travaux de recherche de ce type, dont ceux de Franco Moretti (2011), de Martin Grandjean (2014) et de James et Jason Lee (2017).
Fait à noter, l’importation de l’analyse des réseaux en histoire littéraire et culturelle ne s’est pas faite sans heurts. Johanna Drucker s’en est ainsi pris, dans sa contribution au New Companion to Digital Humanities, à ceux qui surestiment le potentiel heuristique des diverses méthodes de visualisation de données héritées de l’analyse des réseaux, lorsque ces méthodes sont appliquées aussi bien à des individus qu’à des productions culturelles. Elle dénonce ainsi le réductionnisme inhérent, selon elle, à ce type de graphes:
Phenomena in the world of humanistic experience and also in the varied and complex discourse fields of aesthetic documents do not lend themselves to representation within bounded, carefully delimited parameters. The metrics used to weight or characterize humanities phenomena are more complex than single value systems can represent, so a network diagram that shows “relations” among various nodes in a cultural system, among documents, authors, concepts, and so on, that is grounded in a single metric value for the edge-node relations, is painfully reductive. Relationships, whether among human beings or humanistic concepts, are dynamic, fluid, flexible, and changeable. (Drucker: 247)
Quoiqu’il en soit de la justesse ou de la pertinence de cette critique, force est de constater que ce type de bases de données et les outils de visualisation qui lui sont associés gagnent fortement en popularité ces dernières années et qu’ils nous semblaient de fait mériter de figurer au sein d’un panorama de l’utilisation des bases de données dans le champ des études littéraires.
La base de données Figurations: Bilan
La base Figurations a été mise en place dans le cadre du projet de recherche «Figurations romanesques du personnel littéraire en France, 1800-1945» (CRSH, 2008-2011), projet poursuivi sous le titre «L’écrivain en sociétés: imaginaires de la littérature et fictions de la vie littéraire» (CRSH, 2013-2018) et qui avait pour principal objectif de rendre compte, dans une perspective sociocritique, de la façon dont est construit par la fiction l’écrivain comme être social, en constante interaction avec d’autres acteurs, qu’ils soient amis, collaborateurs ou rivaux. Pour mener à bien cet objectif de recherche, le Gremlin s’est doté d’outils théoriques adaptés tels les concepts de «figuration», d’«écrivain fictif» et de «configuration» (Gremlin, 2010) ainsi que de deux bibliographies des récits de la vie littéraire: une pour la France (524 titres parus entre 1801 et 2011) et une pour le Québec (333 titres parus entre 1950 et 2010)13Par récits de la vie littéraire, nous entendons tout récit qui met en scène plus d’un personnage lié à la vie littéraire (écrivains, libraires, éditeurs, journalistes, etc.) ainsi qu’au moins deux personnages liés à la production culturelle au sens large (musiciens, peintres, cinéastes, professeurs d’université, mondains, etc.) Sont ainsi exclus d’emblée les récits présentant un personnage qui se rêve écrivain, mais qui n’écrit jamais, ainsi que ceux centrés autour d’un écrivain solitaire qui n’entre pas en interaction avec d’autres acteurs du champ de production culturelle. .
On le voit, ce corpus, bien que lacunaire, est assez volumineux. C’est que nous avons décidé de ne pas limiter notre analyse aux grandes œuvres, aux grands romans de la vie littéraire, mais bien plutôt de constituer un échantillon le plus représentatif possible du phénomène de la représentation littéraire de l’écrivain et de son milieu. C’est ce qui explique la co-présence, au sein de notre corpus, de textes issus du circuit de grande production et du circuit de production restreinte, si tant est qu’ils puissent être distingués nettement.
L’ampleur du corpus à traiter constitue la principale raison pour laquelle nous avons décidé de mettre en place notre infrastructure de recherche numérique. Il n’était tout simplement pas envisageable d’approcher un corpus aussi vaste œuvre par œuvre. Il nous fallait un outil permettant la mise en série et l’interrogation globale des données recueillies: la base de données Figurations.
Structure de la base et de son interface de gestion
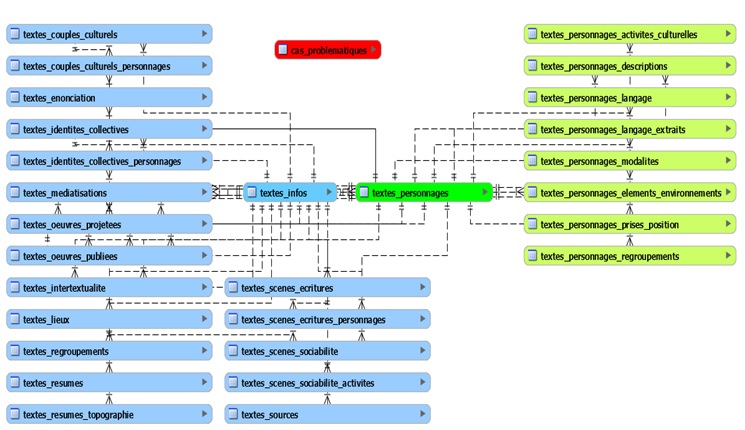
Figure I. Schéma simplifié de la structure de la base de données
MySQL, à la différence d’autres SGBD relationnels tels Microsoft Access ou FileMaker, n’offre pas de fonctionnalité de création de formulaires de saisie. C’est ce qui a motivé la mise sur pied d’un site web conçu avec le langage de programmation PHP, le site Figurations, qui constitue l’interface principale de gestion de notre base de données. L’hébergement de ce site et de notre base de données sur un serveur web permet aux membres du Gremlin de profiter d’un accès délocalisé aux données de la base ainsi qu’à ses divers outils de gestion et d’analyse.
Afin de nous permettre d’explorer la structure et le contenu de la base Figurations, nous nous servirons de cette interface de gestion et, plus particulièrement, de la fiche consacrée aux Jeudis de Madame Charbonneau d’Armand de Pontmartin, journaliste et critique français passé à la postérité pour ses féroces critiques de Balzac. Ce roman à clés satirique, paru en 1862, prend pour cible le milieu de la critique littéraire parisienne et met en scène de façon récurrente les sociabilités du monde des lettres.
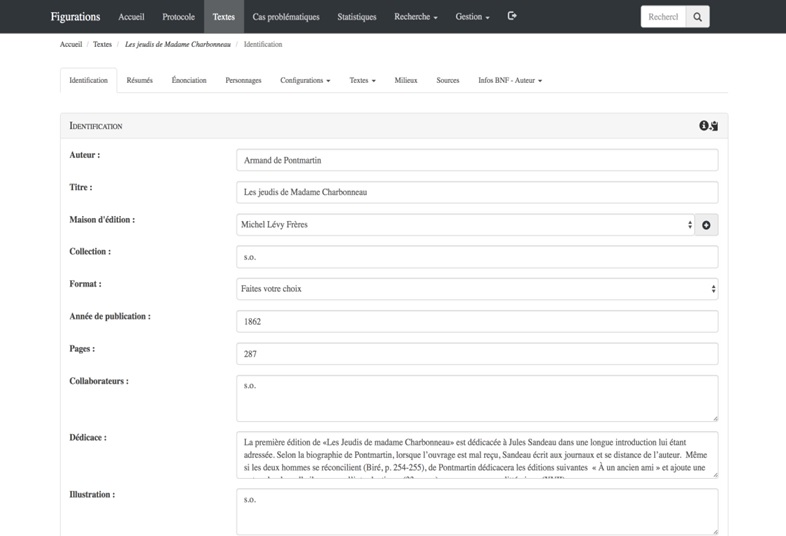
Figure II. Une partie de la fiche consacrée aux Jeudis de Madame Charbonneau
La fiche de lecture est divisée (figure II) en de multiples onglets qui donnent chacun accès au contenu d’une des tables de la base. L’onglet «Identification» regroupe ainsi les données de nature factuelle contenues dans la table «textes_infos»: informations sur l’ouvrage, sur son paratexte, sur sa réception, etc. L’onglet «Énonciation» contient diverses informations concernant la situation d’énonciation mise en scène dans le texte ciblé: identités et caractéristiques du narrateur et de son destinataire, lieu et moment de l’énonciation, etc. Nous voyons bien ici (figure III) comment les données attributives (le contenu des listes) sont associées au sein même de la base à des données textuelles issues des œuvres ciblées (le contenu du champ «Renvois»). Cet entrecroisement de données attributives et de données textuelles est vraiment caractéristique de la base Figurations et c’est ce qui fait qu’on peut la qualifier de base de données hybride.
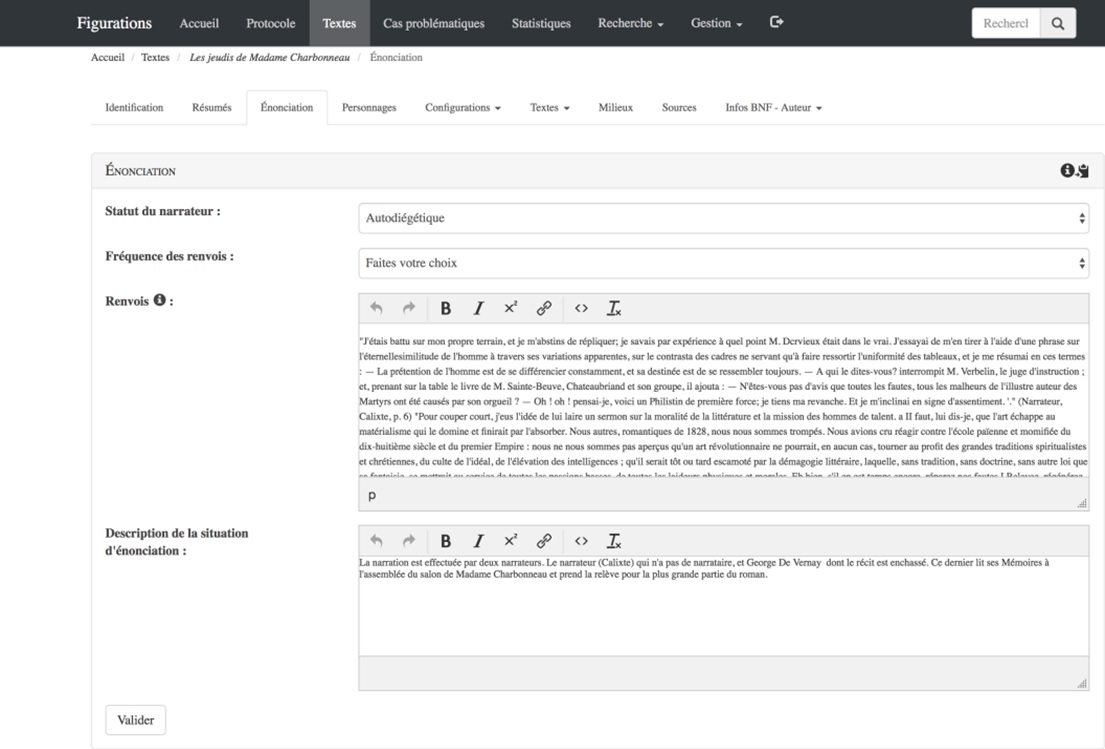
Figure III. L’onglet «Énonciation» de la fiche consacrée aux Jeudis de Madame Charbonneau
La grande majorité des onglets de la fiche regroupent des informations de ce type, des extraits textuels catégorisés. C’est aussi le cas, par exemple, de l’onglet «Intertextualité» qui présente la liste des références intertextuelles repérées par l’analyste.
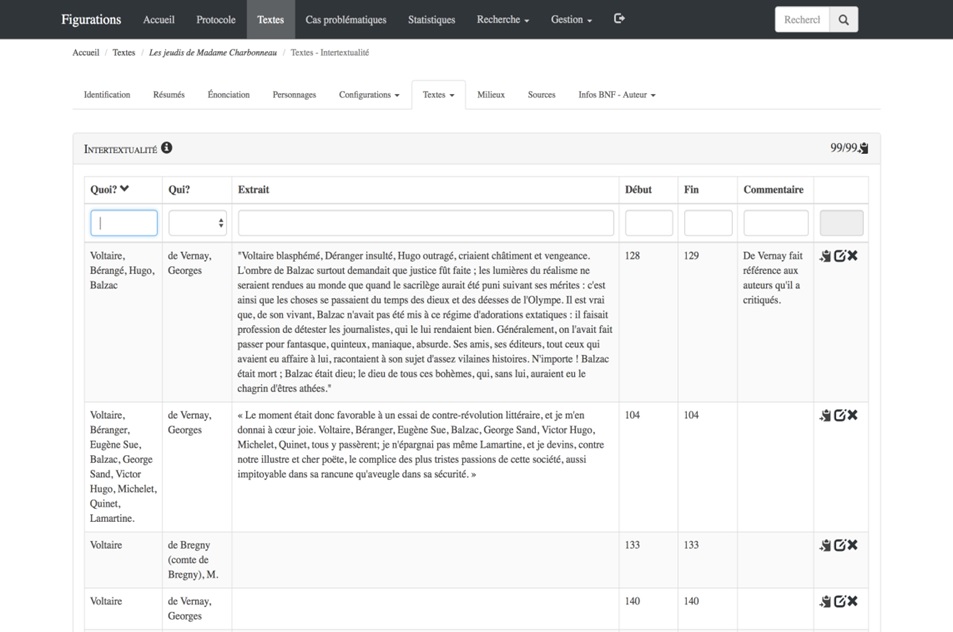
Figure IV. Une partie de l’onglet «Intertextualité» de la fiche consacrée aux Jeudis de Madame Charbonneau
L’onglet «Personnages» rassemble quant à lui une série de sous-fiches consacrées aux divers personnages du roman, sous-fiches elles-mêmes divisées en plusieurs sous-onglets: activités culturelles auxquelles le personnage est associé, informations sur son rapport au langage, prises de position esthétique, politique ou autre, etc. Le contenu de cet onglet ressemble de façon frappante à celui des bases de données prosopographiques décrites dans la première section de cet article, à ceci près que nous sommes ici en présence d’écrivains fictifs.
Le sous-onglet «Catégories» (figure V), seul espace de la base où se trouve consignée une majorité de données non pas textuelles, mais bien plutôt attributives, rassemble quant à lui diverses informations permettant de qualifier le personnage et sa trajectoire au sein de l’espace social mis en scène dans le roman ciblé.
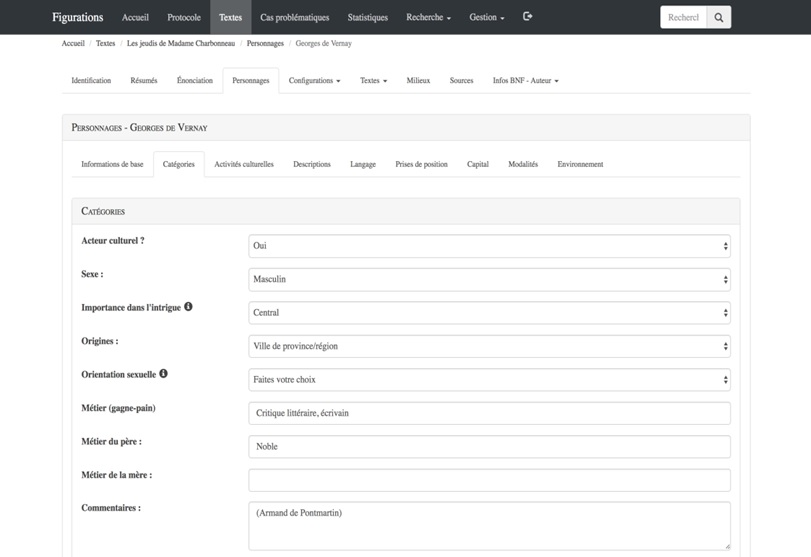
Figure V. Une section du sous-onglet «Catégories» de la fiche consacrée à Georges de Vernay, le personnage central des Jeudis de Madame Charbonneau
On le voit bien ici, notre modèle de données est relativement complexe. De fait, l’encodage des données dans la base par les chercheurs et les nombreux auxiliaires de recherche rattachés au projet a pris beaucoup de temps. Il faut compter, en effet, entre vingt-cinq et quatre-vingts heures de travail pour compléter une seule fiche. On trouve à l’heure actuelle dans la base, 129 fiches dont 115 ont été révisées. On y trouve aussi 2032 fiches personnages dont 1619 sont consacrées à des acteurs de la vie culturelle. De ces mille six cent dix-neuf fiches, six cent soixante et une sont consacrées à des personnages écrivains et cent soixante et un d’entre eux sont considérés comme personnages principaux. On trouve de plus dans la base pas moins de vingt-neuf mille sept cent quarante-deux extraits textuels répartis comme suit:
- Personnages— Descriptions: 11 201
- Intertextualité: 3859
- Personnages— Prise de position: 3432
- Personnages— Activités culturelles: 2149
- Personnages— Capitaux: 2634
- Personnages— Éléments de l’environnement: 2061
- Personnages— Langage: 1992
- Médiatisations: 425
- Œuvres publiées: 408 (ce champ peut contenir plusieurs extraits)
- Débauche: 377
- Scènes d’écriture: 314
- Autres sphères: 292 (ce champ peut contenir plusieurs extraits)
- Œuvres projetées: 262 (ce champ peut contenir plusieurs extraits)
- Identités collectives: 214
- Lieux: 122
Avantages de la transposition numérique de nos données textuelles
On le constate à la lecture de ces chiffres, la masse de données encodées dans la base est imposante. On s’imagine assez facilement la difficulté d’appréhender cet ensemble de données si elles avaient été inscrites sur des fiches papier ou dans des documents de traitement de texte. L’un des principaux profits de l’encodage, de la mise en série, au sein d’une base de données, de nos fiches de lecture consiste justement en la possibilité de les interroger globalement, à peu de frais, et ce, de diverses façons. L’intégration d’un serveur de recherche Sphinx14Sphinx est un moteur de recherche plein texte libre comparable à SOLR et ElasticSearch. au sein de notre infrastructure numérique permet ainsi d’effectuer des recherches plein texte au sein de l’ensemble des champs textuels de la base.
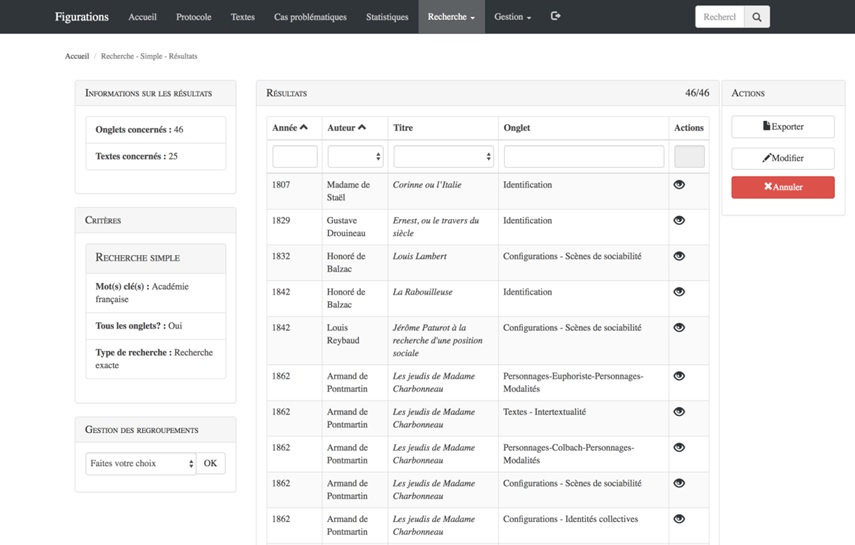
Figure VI. Une partie des résultats d’une recherche plein texte au sein de l’ensemble des onglets de la base pour le terme «Académie française».
Le serveur renvoie à l’usager la liste des onglets (et des fiches) concernés par la requête. L’usager peut aussi limiter la recherche aux onglets (et donc aux tables) de la base qui l’intéressent plus précisément. Ce type de recherche, bien que très utile pour délimiter rapidement des corpus d’œuvres potentiellement intéressantes en fonction du sujet traité —on peut chercher, par exemple, l’ensemble des fiches qui mentionnent l’Académie française (figure VI)— est assez limité. C’est pourquoi nous avons développé dans le cadre de ce projet d’autres moyens d’appréhender de façon globale notre corpus.
Le site offre ainsi différents outils de visualisation fondés sur des requêtes généralement préprogrammées. Ces outils permettent, chacun selon ses modalités propres, d’interroger le corpus dans son ensemble. On trouve par exemple dans cet onglet un lien vers un nuage de mots tirés de la table «Intertextualité». On voit ici (figure VII) que Balzac, Hugo, Molière et Shakespeare dominent le palmarès des références intertextuelles recensées dans les textes de notre corpus, état de fait significatif, mais dont l’analyse reste à effectuer.
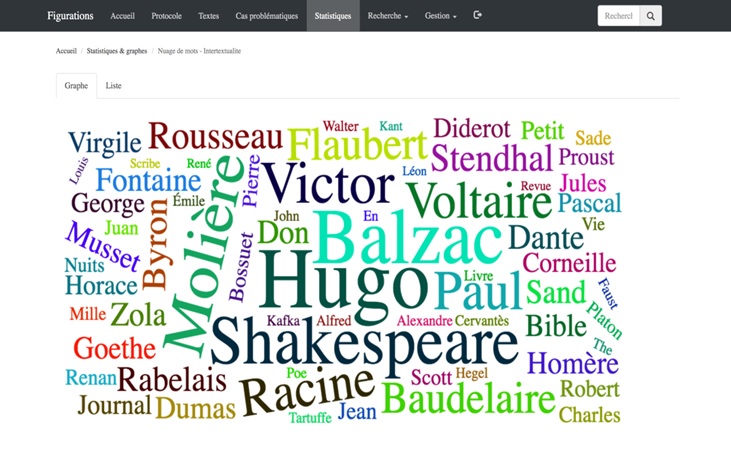
Figure VII. Un nuage de mots construit à partir des données de l’onglet « Intertextualité»
Les divers modules de visualisation des données présents sur le site ont surtout comme intérêt de proposer à l’usager des points de départ pour pousser plus loin l’analyse. C’est le cas, par exemple, de ce graphe (figure VIII) qui présente l’évolution, selon diverses périodes temporelles découpées aléatoirement (par tranches de cinquante ans), de divers motifs liés aux trajectoires des personnages centraux des récits de notre corpus: description des débuts dans l’écriture, de la première publication, de la chute du personnage principal dans la misère ou, au contraire, d’un gain de richesse, abandon de la carrière littéraire, chute dans la folie ou tentative (réussie ou non) de suicide. Est-ce que le roman représente la trajectoire d’un de ces personnages écrivains qui, tel le Georges Duroy du Bel-Ami de Maupassant, commencent le roman «la poche vide» (Maupassant: 31) et le terminent riche, «un des maîtres de la terre» (Maupassant: 413)? On voit, grâce à la légende du bas, que les colonnes en bleu font référence aux œuvres publiées entre 1800 et 1849, celles en noir à celles publiées entre 1850 et 1899, celles en vert à celles publiées entre 1900-1949 et, finalement, celles en orange à celles publiées de 1950 à aujourd’hui.
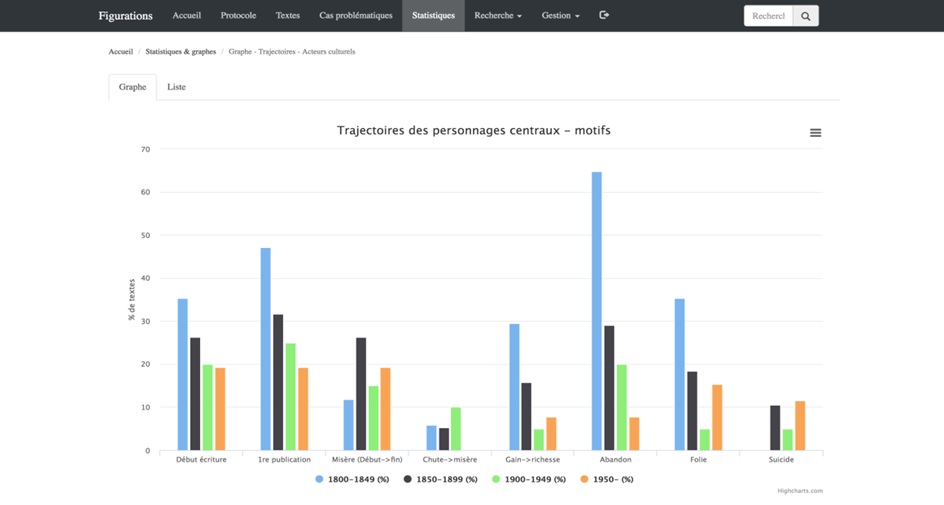
Figure VIII. Graphe des trajectoires des personnages centraux
Plusieurs aspects de ce graphe suscitent des interrogations. Que penser, en effet, de cette diminution constante du motif de type «Gain de richesse» du début du XIXe siècle à nos jours? Pourquoi convoque-t-on de moins en moins, au fil du temps, le trope de la première publication des personnages écrivains? Et que dire, enfin, de la présence massive (près de 65% d’entre elles le reconduisent) du scénario de l’abandon de la carrière littéraire dans les œuvres de cette époque? On le voit bien ici, les requêtes préprogrammées de ce type suscitent beaucoup de questions. En fait, elles suscitent plus de questions qu’elles n’offrent de réponses.
C’est ce qui nous amène au deuxième profit heuristique important de l’encodage des données de notre projet de recherche dans une base de données, la possibilité de croiser, de façon très précise, les informations recueillies. Ce croisement des informations s’effectue, au sein de notre infrastructure, grâce à l’outil de recherche avancée (figure IX). Cet outil permet de cibler et de croiser l’information contenue dans l’ensemble des onglets de l’ensemble des fiches de la base. Il se décline en deux versions: une version qui permet de cibler les textes et une autre version qui permet de cibler les personnages. On peut ainsi, par exemple, reproduire facilement la requête ayant servi à créer le graphe de la figure VIII en ciblant les personnages centraux ayant abandonné, dans les œuvres publiées entre 1800 et 1849, la carrière littéraire. On apprend ainsi en lançant cette requête que onze personnages centraux de récits publiés entre 1800 et 1849 abandonnent l’écriture. On peut essayer d’y voir plus clair en modifiant cette requête pour savoir si cet abandon est généralement lié à l’incapacité des personnages à se faire publier. Cela ne semble pas être le cas puisque neuf d’entre eux ont réussi à se faire publier à la fin du roman. On peut aussi se questionner sur l’impact du genre et se demander si les personnages féminins abandonnent plus souvent la partie que leurs confrères masculins.
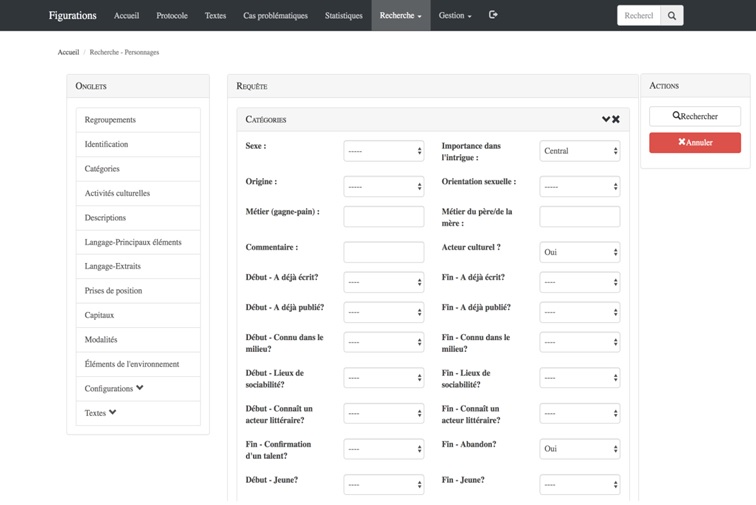
Figure IX. L’outil de recherche avancée de personnages
L’outil de recherche avancée nous permet de constater que cinq des sept récits de notre corpus publiés entre 1800 et 1850 présentant des personnages principaux féminins mettent en scène l’abandon de leur carrière littéraire. C’est le cas, par exemple, du personnage principal de La muse du département de Balzac, Dinah de la Baudraye, écrivaine de province, qui cherche à Paris la gloire, et qui, désabusée par ses déboires amoureux et artistiques, se retire à Sancerre, enceinte d’une fille, et retourne à sa famille et au mariage. Tout ceci peut nous amener à croire que l’on ne saurait, pour traiter de la présence massive de l’abandon de la carrière littéraire dans les œuvres de notre corpus publiées à cette époque, faire l’économie d’une réflexion sur l’histoire de l’évolution du statut de la femme et du ou des rôles qu’elle s’est vue attribuer, imposer plutôt, dans et à travers le discours social contemporain15Denis Saint-Amand a d’ailleurs proposé dans un article récent (2018), et ce, en mobilisant les données de notre base, diverses pistes de lecture concernant le personnage de «la femme de lettres dans le roman français du XIXe siècle». . Il ne s’agit pas, bien sûr, d’une grande révélation, mais le fait est que cet outil de recherche avancée offre à l’usager un moyen simple, rapide et très efficace de tester des hypothèses et ainsi de mettre au jour des pistes de recherche qui pourront mener à des relectures fécondes du corpus ou d’un sous-corpus.
La façon dont les données textuelles sont structurées dans notre base permet, soulignons-le, de les exporter facilement vers différents logiciels d’analyse. Ainsi peut-on produire très rapidement un fichier texte qui rassemble l’ensemble des descriptions de personnages apparaissant dans des ouvrages de notre corpus. Ce fichier peut ensuite être importé dans un logiciel d’analyse textuelle automatisée tel Tropes ou Voyant Tools.
Notons que ces données textuelles peuvent être consultées directement à l’aide d’une interface de programmation applicative (en anglais, application programming interface ou API) mise en place il y a bientôt trois ans et qui renvoie en réponse à une requête précise les données brutes de la base. Les données de la figure X↑, qui présente les vingt premiers extraits consacrés à des scènes d’écritures des œuvres de notre corpus publiées après 1900, sont ainsi récupérées automatiquement à chaque chargement du présent article.
Cette API facilite la création de petits logiciels permettant d’interroger les données de la base de façon très souple. Nous avons ainsi mis sur pied dernièrement un petit script Python qui récupère les données textuelles de Figurations et effectue diverses opérations (nettoyage des données, découpage du texte en mots, lemmatisation de ces mots) afin de repérer les bigrammes les plus récurrents dans les extraits textuels ciblés.
La présence, au sein de notre infrastructure, de nombreuses données attributives, objectivées, nous permet aussi de mobiliser des logiciels d’analyse statistique permettant des calculs plus complexes que ceux, forts simples, qui sont au fondement des graphes présentés ci-dessus. On trouve ainsi dans l’onglet «Statistiques» diverses pages qui permettent de communiquer, grâce au cadriciel OpenCPU, avec une instance du logiciel d’analyse statistique R fonctionnant sur notre serveur. On voit ici (figure XI), par exemple, un tel outil développé dans le cadre de ce projet et qui permet d’explorer, en s’appuyant sur l’analyse des correspondances multiples, les trajectoires des personnages des récits de notre corpus. Il permet par exemple de visualiser rapidement les liens potentiels entre l’orientation sexuelle d’un personnage, son origine géographique, le fait qu’il soit jeune ou non au début du roman et deux éléments de sa trajectoire: est-ce que le roman raconte sa première publication et est-ce que le roman raconte son ascension sociale.
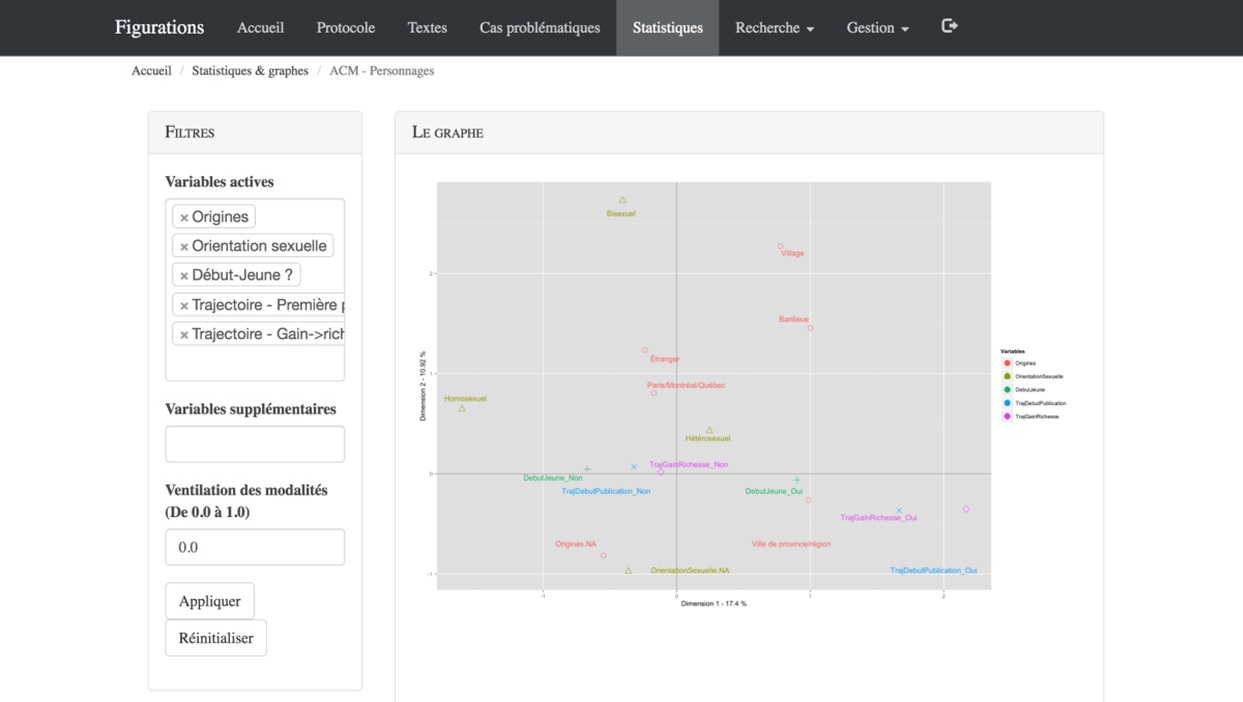
Figure XI. L’outil d’analyse des correspondances multiples— Personnages
Ces trois avantages, ces trois possibilités offertes par l’encodage des données de notre projet de recherche (interrogation globale d’un vaste corpus, croisement des informations encodées et mobilisation de logiciels d’analyse textuelle et statistique) justifient amplement à notre avis les efforts et le temps investis dans l’encodage de nos données de recherche dans Figurations. Soulignons, tout de même, dans le cadre de ce bilan, que ce processus d’encodage a parfois posé problème.
De quelques défis posés par l’encodage des données de notre base
Un des principaux défis auxquels nous avons dû faire face dans le cadre de ce processus découle en grande partie de l’importante marge de manœuvre laissée à l’analyste par la structure de la fiche de lecture. Un lecteur de Bel-Ami pourrait bien décider, par exemple, que la scène qu’il est en train de lire ne constitue pas vraiment une scène d’écriture et qu’elle ne doit pas, de fait, être intégrée à la base de données, alors qu’un autre lecteur, moins pointilleux, l’y ajouterait. On peut aussi s’interroger sur la capacité d’un seul lecteur à repérer l’ensemble des traces d’intertextualité présentes dans un roman. Nous avons d’ailleurs mis en place, afin de minimiser l’impact négatif de ces oublis ou de ces erreurs d’interprétation, un protocole de relecture des textes. Toujours est-il que la nature même des données recueillies et des objets ciblés par notre projet fait en sorte qu’il subsistera toujours un certain flou, une certaine variabilité interprétative avec laquelle nous sommes obligés de composer lors de l’analyse des données recueillies.
Un autre défi auquel nous nous sommes heurtés dans le cadre du processus d’encodage des données du projet concerne ces textes qui fonctionnent trop bien, qui cadrent trop parfaitement avec notre fiche de lecture. C’est le cas, par exemple, d’Illusions perdues de Balzac. C’est aussi le cas d’un roman méconnu, Jacques Arnaut et la Somme Romanesque de Léon Bopp, roman qui fit l’objet d’une communication de Michel Lacroix prononcée dans le cadre d’une journée d’études du Gremlin et lors de laquelle ce dernier décrivait le problème posé par cet ouvrage:
Jacques Arnaut met à mal [notre] méthode. Par le caractère proliférant de sa dimension métalittéraire, ce roman constitue une œuvre-limite, à ce point imprégnée des considérations et préoccupations qui animent notre projet, qu’elle paraît « insaisissable ». Tout se passe ainsi, à la première lecture, comme si la fiche allait en reproduire intégralement les quelque 600 pages. Quel est l’intérêt de la sélection d’extraits, si tout retient l’intérêt? Les mailles du filet seraient-elles, dans ce cas, trop serrées? (Lacroix, 2010: 115-116)
Quel intérêt y aurait-il, en effet, à recopier dans les petites cases de notre base de données tout le texte de Jacques Arnaut ou d’Illusions perdues? Nous nous retrouvons donc confrontés à une situation quelque peu paradoxale: notre base de données qui traite des romans de la vie littéraire ne contient pas de fiches consacrées à ces œuvres qui incarnent pourtant parfaitement notre objet.
Un autre problème qui a compliqué l’encodage des données peut être résumé ainsi: il y a des œuvres auxquelles il est impossible d’appliquer notre grille de lecture. La façon dont elles représentent la vie littéraire ne semble pas, en effet, pouvoir être captée adéquatement à l’aide de notre base de données. Fait à noter, ces œuvres appartiennent pour la plupart à la littérature contemporaine. Il faut garder à l’esprit, pour bien comprendre cette situation, que notre projet initial, dans le cadre duquel a été conçue notre base de données, ne ciblait que des textes publiés entre 1800 et 1945. Ce n’est que dans un deuxième temps, en 2013, que nous avons décidé de cibler deux nouveaux corpus : la littérature québécoise et la littérature française contemporaine. De fait, soixante-dix-sept fiches avaient été créées avant qu’apparaisse dans notre corpus un premier roman publié après 1950: La fille de papier de Guillaume Musso, roman à forte dimension métalittéraire qui met en scène un écrivain en proie à l’angoisse de la page blanche qui voit s’incarner l’héroïne du roman qu’il est en train d’essayer d’écrire, et au sein duquel pullulent les références intertextuelles.
Or, la base de données a été pensée en grande partie pour répondre à des besoins de recherche suscités par l’analyse de la figuration de la vie littéraire telle qu’elle se présente dans des romans du XIXe siècle tels Bel-Ami et Illusions perdues. Il y a cependant, dans de nombreux cas, de profondes différences formelles, notamment au niveau de l’énonciation, de la structure du récit et de l’hybridité générique, entre les romans réalistes du XIXe siècle et les romans contemporains. De fait, nous avons été forcés de revisiter notre modèle de données en cours de route et d’ajouter ou, du moins, de modifier certains champs pour mieux prendre en compte certaines particularités du corpus contemporain. La plupart de ces modifications étaient mineures, et ce, pour une très bonne raison: nous ne pouvions nous permettre de modifier en profondeur notre fiche de lecture sans que les fiches déjà produites deviennent soudainement caduques. Nous nous sommes par exemple contentés d’ajouter dans la liste des statuts du narrateur de l’onglet «Énonciation» une catégorie «Problématique» pour signaler les œuvres qui mettent en scène une narration complexifiée. On peut croire que la structure de notre base de données aurait été très différente si nous avions prévu dès le départ l’intégration d’un corpus d’œuvres contemporaines.
Les lecteurs ont dû, à deux reprises, s’avouer vaincus l’œuvre ciblée ne pouvait tout simplement pas être analysée avec notre protocole sans que l’on perde la majeure partie de ce qui fait son intérêt pour nos objectifs de recherche. Ce fut le cas du texte de l’écrivaine québécoise Yolande Villemaire, La Vie en prose, au sein duquel se font entendre une douzaine de personnages féminins à l’identité mouvante, ceux-ci n’étant jamais identifiés clairement, ce qui rend bien souvent impossible leur identification formelle et donc leur insertion dans les «petites cases» de notre base de données. Un problème semblable s’est posé avec Louve–Basse de Denis Roche. Cet état de fait, cette présence, au sein de notre corpus, de ces œuvres insaisissables, de ces textes intraitables, nous a d’ailleurs amenés à ajouter à notre base de données une table (et un onglet correspondant sur le site Figurations) au sein de laquelle est consignée la liste de ces textes et des raisons qui ont poussé les chercheurs à abandonner leur analyse. On touche ici de toute évidence à l’une des limites de notre modèle de données, de notre volonté affichée d’objectiver, en partie du moins, la représentation de la vie littéraire et, par-delà, de cette volonté de mettre «la beauté en boîtes» (Prunel: 4), pour reprendre l’expression rapportée par Béatrice Joyeux-Prunel dans un texte consacré, justement, à cette tension entre l’incommensurabilité supposée de l’art et notre volonté de le quantifier.
Conclusion
On l’a vu tout au long de ce texte, Figurations constitue un exemple intéressant de base de données hybride, qui se démarque de la multitude de bases de données textuelles présentes dans le champ des études littéraires par son intégration de nombreuses données attributives qui facilitent la mobilisation d’outils et de logiciels d’analyse de toutes sortes. Grâce à la mise en série d’un ensemble d’extraits textuels annotés et catégorisés, notre base permet une appréhension globale du phénomène de la représentation fictive de la vie littéraire. Elle répond ainsi de façon exemplaire, nous semble-t-il, à l’injonction de Matthew Jockers citée en exergue de cet article et dans laquelle ce dernier affirme avec force la nécessité de joindre le distant reading à la pratique plus traditionnelle du close reading.
Ceci étant dit, une question demeure. Serait-il possible, maintenant que ce projet est achevé, de maximiser le potentiel de diffusion et, surtout, d’exploitation du contenu de notre base? Nous avons déjà fait quelques efforts en ce sens. Nous avons ainsi intégré, au sein de la section du site du groupe consacrée au projet Figurations, une interface16Cette interface de Figurations est accessible à l’adresse suivante: http://legremlin.org/index.php/figurationsprojet/figurationsleprojet. de consultation de la base en accès libre. Nous avons, de plus, mis en place à l’automne 2016 l’API mentionnée précédemment. Il n’empêche que, pour l’instant, malgré ces efforts, les données de Figurations restent relativement confidentielles. Ces informations sont-elles condamnées à rester lettre morte après la fin des travaux de notre groupe? Nous présenterons, en guise de conclusion, quelques pistes de solutions qui permettraient de remédier quelque peu à ce problème, à ce relatif cloisonnement de nos données.
Nous pourrions, dans un premier temps, envisager d’exposer nos données dans le web de données ouvertes et liées. Le défi posé par une telle opération n’est pas d’ordre technologique. Depuis la création, en 2012, du R2RML17Le R2RML (Relational database to RDF Mapping Language) permet de formaliser la mise en correspondance d’un modèle de données d’une base de données relationnelle avec le format structurant la plupart des jeux de données du web de données ouvertes et liées, le Resource Description Framework (RDF). , et de diverses solutions logicielles l’implémentant (D2RQ, R2RML Parser, Virtuoso, etc.), il est, en effet, relativement aisé de traiter les données d’une base relationnelle afin de permettre leur intégration dans le web de données ouvertes.
Le problème se situe plutôt au niveau de notre modèle de données. Transposition numérique d’une fiche de lecture, ce modèle de données est fortement orienté en fonction des objectifs de recherche du Gremlin. De plus, le travail sur la base ayant commencé tout au début de la vague d’engouement pour l’ouverture de données (la première version de DBpedia, navire amiral du web de données ouvertes, date de janvier 2007, celle d’Europeana fut lancée en novembre 2008, Data.bnf.fr date de 2011, etc.), ce dernier n’a pas été pensé en fonction de la diffusion de nos données sur le web de données ouvertes. Il ne tient cependant qu’à nous d’aligner, en tout ou en partie, notre modèle de données avec des ontologies et des vocabulaires existants et populaires pour maximiser la compatibilité de nos données de recherche ainsi structurées avec celles qui circulent déjà sur le web de données ouvertes. Nous pourrions, par exemple, nous servir du Web Annotation Data Model18La description de ce modèle de données est accessible à l’adresse https://www.w3.org/TR/annotation-model/. développé par le W3C pour les données liées aux extraits d’œuvres littéraires colligés dans notre base, du vocabulaire Friend of a Friend 19La description de ce vocabulaire est accessible à l’adresse http://xmlns.com/foaf/spec/. (FOAF) pour celles qui concernent les relations établies entre les personnages de notre corpus, du modèle Functional Requirements for Bibliographic Records 20La description de ce modèle de données est accessible à l’adresse suivante: https://www.ifla.org/publications/functional-requirements-for-bibliographic-records. (FRBR) pour les informations bibliographiques contenues dans notre base, et ainsi de suite.
L’alignement de notre modèle de données sur des ontologies et vocabulaires préexistants faciliterait, de plus, l’importation au sein de l’interface de gestion et d’analyse de la base Figurations des données colligées par des projets de recherches apparentés. On pourrait ainsi envisager de mettre en relation les informations recueillies sur les trajectoires d’acteurs littéraires fictifs de notre corpus avec celles concernant les trajectoires des acteurs littéraires, bien réels, rassemblées dans la Base de données sur la Vie littéraire au Québec ainsi qu’avec les données sur les trajectoires des éditeurs contenues dans la Base de données sur les gens du livre au Québec développée par le Groupe de recherches et d’études sur le livre au Québec (GRÉLQ).
Notre deuxième série de propositions vise à répondre à certaines lacunes soulevées ci-dessus et est orientée en fonction d’une réutilisation, à l’interne, de la masse de données accumulées. Ainsi, comme mentionné ci-dessus, l’un des principaux problèmes de notre grille de lecture se situe au niveau de ces œuvres qui correspondent trop bien à notre modèle. La création d’une fiche consacrée à Illusions perdues prendrait ainsi, on peut se l’imaginer, un temps considérable. Ne serait-il pas possible d’automatiser en partie la création d’une telle fiche en nous servant d’un classificateur automatique? L’apprentissage automatique nécessite en effet le ground truth data, la vérité terrain, rôle qui pourrait très bien être joué par les milliers d’extraits textuels catégorisés contenus dans notre base. Il serait ainsi envisageable de produire un classificateur qui, nourri de ces milliers d’extraits, serait en mesure de repérer, dans n’importe quel corpus textuel, d’autres extraits correspondant à nos objectifs de recherche. On pourrait, par exemple, repérer dans un roman choisi au hasard les scènes d’écriture ou de descriptions de personnages écrivains. Un tel outil pourrait aussi servir à faire notre propre autocritique. Pour les œuvres dont le texte complet est disponible sur Internet, ne serait-il pas possible, en effet, de «vérifier» d’une certaine façon si nous n’avons pas raté quelque chose? Un tel outil pourrait aussi être appliqué à des corpus de textes non étudiés, aux centaines de récits de notre bibliographie qui n’ont toujours pas fait l’objet d’analyse ou de façon plus ambitieuse, aux corpus numérisés de Gallica et de la Bibliothèque et archives nationales du Québec. Il y a vraiment ici, nous semble-t-il, un filon à creuser.
Bibliographie
- 1Roberto Busa est un prêtre jésuite italien qui s’est donné pour mission, en 1946, d’étudier le lexique de la présence et de l’incarnation dans les œuvres de Saint-Thomas d’Aquin, vaste corpus de plus de onze millions de termes. Aidé en cette tâche par IBM (International Business Machines Corporation), il effectua une lemmatisation complète du corpus aquinien, aventure qui dura plus de trente ans et qui aboutit à la constitution du Corpus thomisticum qui est aujourd’hui consultable en ligne, dans sa version latine origine, à l’adresse http://www.corpusthomisticum.org/.
- 2Premier corpus de texte en anglais contemporain, le Brown Corpus for Use On Digital Computers fut mis en place dans les années 60 à l’Université de Brown par W. Nelson Francis et Henry Kučera.
- 3Le Thesaurus Lingua Graecae, mis en place en 1972, contient les principaux textes de l’antiquité grecque depuis Homère jusqu’à l’an 200 après Jésus-Christ.
- 4L’Oxford Text Archive a été mise sur pied en 1976 par Lou Burnard, qui s’était donné pour mission d’archiver et de rendre accessibles à qui en avait besoin des copies électroniques de textes encodés préalablement par d’autres chercheurs pour des projets spécifiques.
- 5Cette base de données a été créée au cours des années 70 afin de fournir des exemples pour le Trésor de la Langue Française et qui a alimenté dans les décennies suivantes un nombre impressionnant de travaux de lexicométrie et d’analyse textuelle automatisée.
- 6Fondé en 1997, le Orlando Project est accessible à l’adresse http://www.artsrn.ualberta.ca/orlando/.
- 7Le site web du projet est accessible à l’adresse http://hyperroy.nt2.uqam.ca.
- 8Ce projet vise à mettre en place une édition électronique du corpus de la poésie scaldique qui contient près de 5800 stances en vieux norrois.
- 9Prelia est accessible en ligne à l’adresse http://prelia.fr.
- 10Ce répertoire est accessible en ligne à l’adresse http://nt2.uqam.ca.
- 11Le site web de ce projet est accessible en ligne à l’adresse http://republicofletters.stanford.edu/.
- 12Le site web de ce groupe est accessible en ligne à l’adresse http://artlas.ens.fr/fr/.
- 13Par récits de la vie littéraire, nous entendons tout récit qui met en scène plus d’un personnage lié à la vie littéraire (écrivains, libraires, éditeurs, journalistes, etc.) ainsi qu’au moins deux personnages liés à la production culturelle au sens large (musiciens, peintres, cinéastes, professeurs d’université, mondains, etc.) Sont ainsi exclus d’emblée les récits présentant un personnage qui se rêve écrivain, mais qui n’écrit jamais, ainsi que ceux centrés autour d’un écrivain solitaire qui n’entre pas en interaction avec d’autres acteurs du champ de production culturelle.
- 14Sphinx est un moteur de recherche plein texte libre comparable à SOLR et ElasticSearch.
- 15Denis Saint-Amand a d’ailleurs proposé dans un article récent (2018), et ce, en mobilisant les données de notre base, diverses pistes de lecture concernant le personnage de «la femme de lettres dans le roman français du XIXe siècle».
- 16Cette interface de Figurations est accessible à l’adresse suivante: http://legremlin.org/index.php/figurationsprojet/figurationsleprojet.
- 17Le R2RML (Relational database to RDF Mapping Language) permet de formaliser la mise en correspondance d’un modèle de données d’une base de données relationnelle avec le format structurant la plupart des jeux de données du web de données ouvertes et liées, le Resource Description Framework (RDF).
- 18La description de ce modèle de données est accessible à l’adresse https://www.w3.org/TR/annotation-model/.
- 19La description de ce vocabulaire est accessible à l’adresse http://xmlns.com/foaf/spec/.
- 20La description de ce modèle de données est accessible à l’adresse suivante: https://www.ifla.org/publications/functional-requirements-for-bibliographic-records.